

What it is
This project trains a convolutional neural network to recognise flower species from the Oxford 102 dataset. It sounds gentle, but it is a surprisingly awkward computer vision task. Some species look almost identical at a glance, while the same species can change dramatically with lighting, background, growth stage, and camera angle.
I treated it as a full modelling exercise rather than just a notebook experiment. The work included preprocessing, augmentation, architecture design, hyperparameter tuning, training on university compute, and checking where the model failed.
Model approach
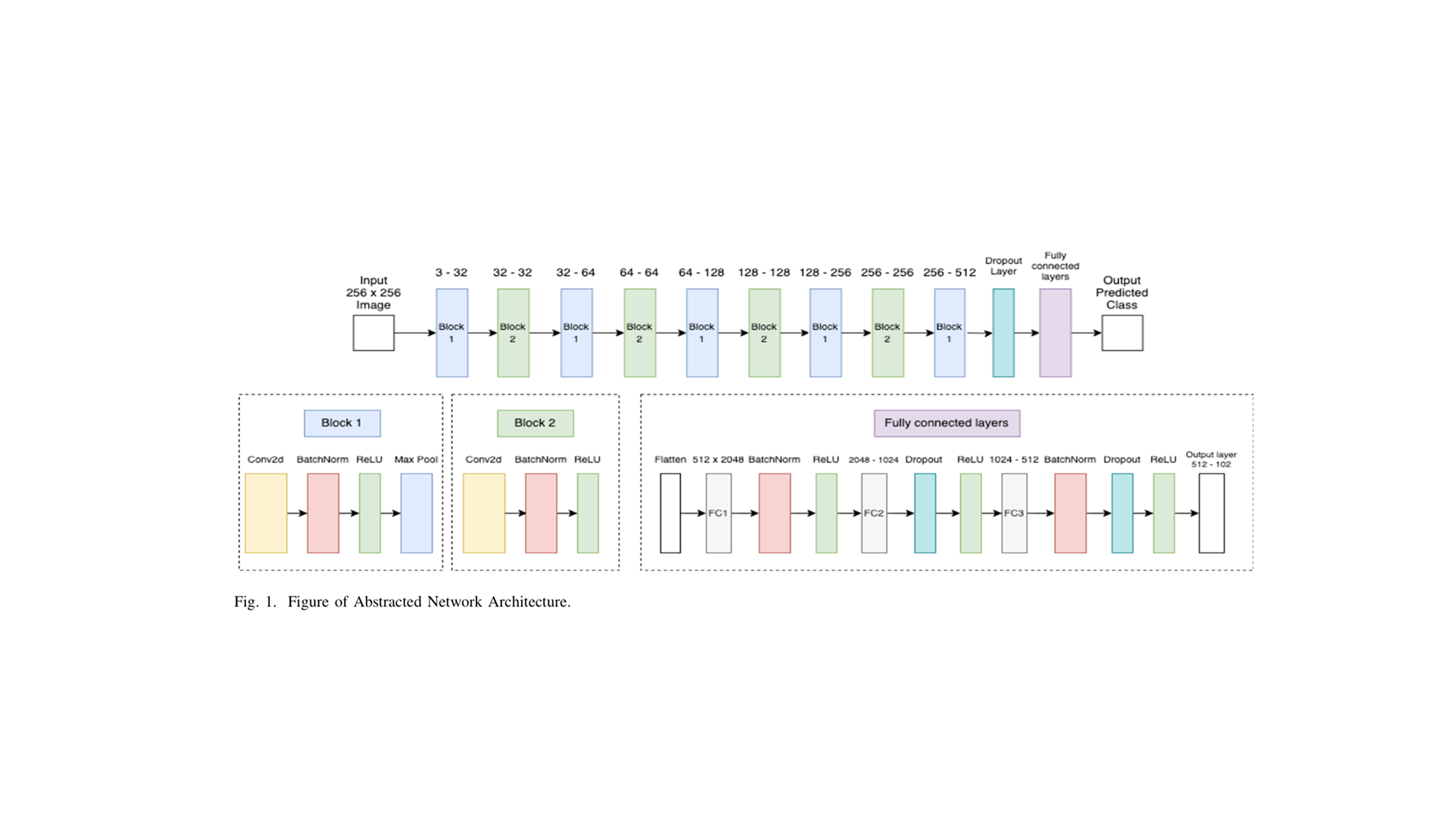
The model is a custom PyTorch CNN built for 102 output classes. Images are resized to 224 by 224 pixels, then passed through stacked convolution blocks with batch normalization, ReLU activations, max pooling, and dropout. The classifier head uses fully connected layers to turn the learned feature maps into class probabilities.
The architecture borrows the general pattern of VGG-style feature extraction, but keeps the implementation small enough to reason about. I wanted to understand how the model was learning rather than hide everything behind a pretrained network on the first pass.
Technical build
Training setup
The training pipeline uses PyTorch transforms for resizing, random rotation, horizontal and vertical flips, colour jitter, affine transforms, random crops, tensor conversion, and normalization. The training split is small, so augmentation is not decorative here. It is doing real work by making the model less fragile.
Compute and optimization
Training ran on the University of York Viking HPC cluster using an NVIDIA H100 GPU. The model used cross-entropy loss and Adam optimization with weight decay. I tested learning rates, batch sizes, and epoch counts, then used validation performance to avoid choosing settings only because they looked good on the training curve.
Result
The final model reached 75.12% test accuracy. It performed best on visually distinctive flowers and struggled where classes shared very similar petal shapes or colours. That failure mode was useful because it matched the real difficulty of the dataset, and it pointed toward the next sensible improvements: stronger augmentation, transfer learning, and attention-style mechanisms for subtle visual differences.